Storing data at scale
An example with HDFS
It's not all about software

Vertical & horizontal scaling
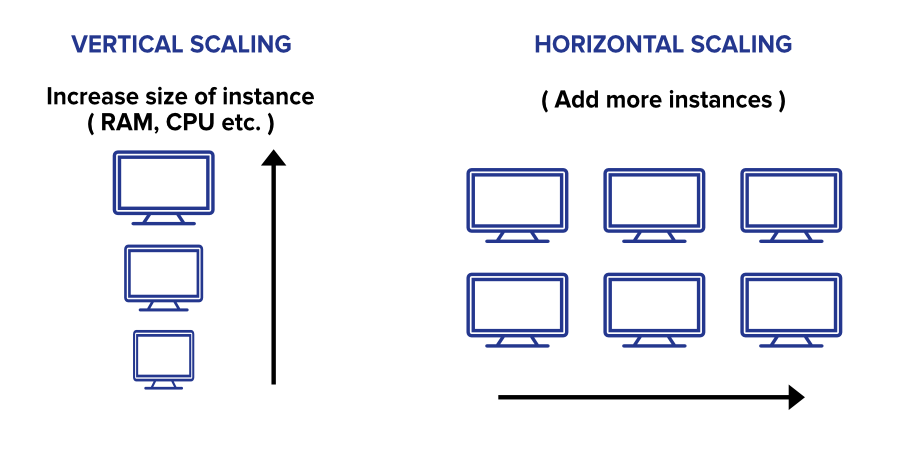
- Limits to vertical scaling (Yahoo and Google experienced that early): You can’t just make a server bigger and bigger without reaching limits
- Horizontal scaling enables to circumvent these limitations by distributing storage of data and compute (transformation of data) across multiple machines
- Horizontal scaling requires specific technologies to manage a number of challenges
- Fault tolerance (probability of losing a node is higher)
-
Splitting computation tasks across multiple machines
-
But horizontal scaling is no panacea: it brings additional complexity and overhead, and should be seen only as a last resort. There are other options to consider first.
Hadoop & HDFS
- Hadoop is the name of an entire ecosystem dedicated to the management of big data
- HDFS means Hadoop Distributed File System and is a technology to store data at scale
- HDFS is a file management system, not a database
Hadoop Distributed File System (HDFS): a solution for distributing storage
- Reasons for storing across multiple files
- If data is big (billions of rows), data may not fit in a single file / hard drive disk, we can distribute the way data is stored
- Offer parallelism when we want to compute things (eg. Filtering billions of rows as part of a single processing)
- Data storage is in plain text file and is distributed across multiple files and machines
- Files can be in different formats such as txt but other formats are allowing for more compression (parquet)
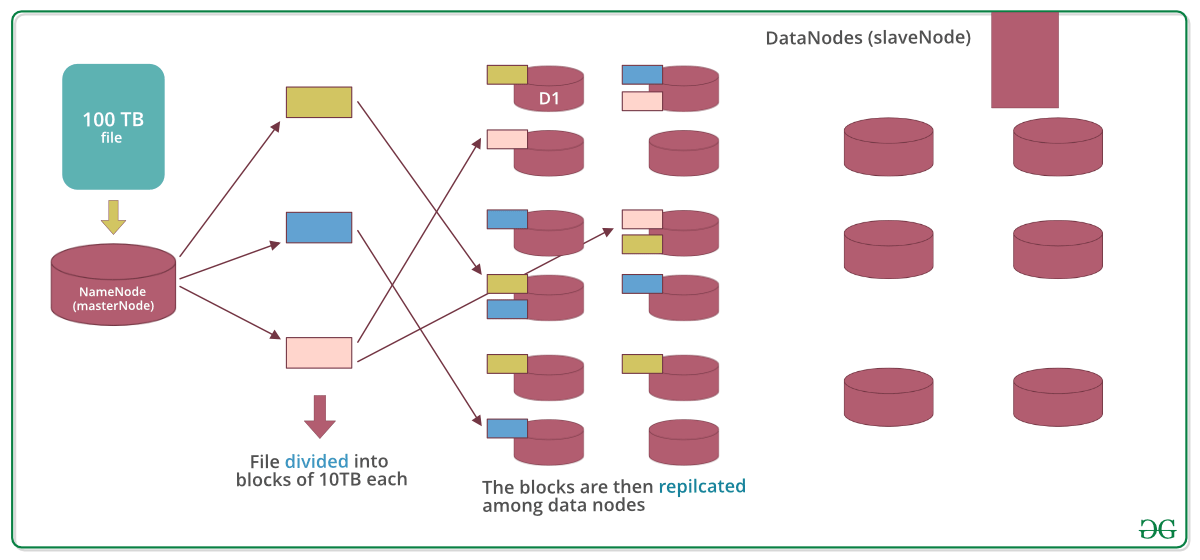
- If we want to store more data, we can simply add more machines to the cluster that we have instead of buying a larger hard drive
-
In modern implementation service of HDFS (i.e. AWS S3), the complexity of adding more resources is abstracted away from the users. We just ask AWS for more storage space
-
HDFS is made up of nodes which can be physical machines or virtual machines
- Name node has full visibility on data distribution, handle fault tolerance, data distribution and replication across data nodes, etc.
- This is a typical master/slave controller/worker type of framework
- Data blocks are going to be distributed across nodes in a way that is fault tolerant